# Stream API
# 前言
Java 8 中有两大最重要的改变。第一个是 Lambda 表达式;另外一个则是 Stream API(Java.util.stream.*)。
Java 8 为我们提供了 Stream 流,那么它到底是什么呢?
它其实就是一道数据渠道,用来操作(集合,数组等)所生成的元素序列。
# 注意
- Stream本身不会存储元素。
- Stream 不会改变源对象。相反,他们会返回一个存有结果的新Stream。
- Stream 操作是延迟执行的。这意味着他们会等到需要结果时才会执行。
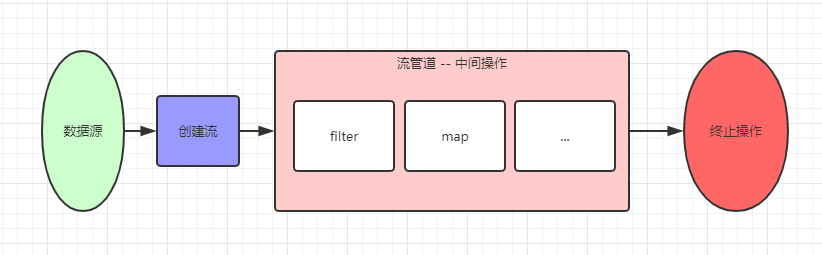
# 流程
创建流
一个数据源(如:集合、数组),获得一个流。
中间操作
一个中间操作链,对数据源进行数据处理。
终止操作
一个终止操作,执行中间操作链,并产生结果。
# 创建流
Java 8 中的 Collection 接口被扩展,提供了两个获取流的方法。
default Stream<E> stream(); // 返回一个顺序流
default Stream<E> parallelStream(); // 返回一个并行流
2
而它也可以通过数组、值、函数等创建流,也可以创建无限流。
但是日常中我们使用的最多的就是通过Collection接口扩展的获取流方法来创建 Stream 。
使用Collection接口提供的两个方法创建流。
List<String> list = new ArrayList<>(); // List 是Collection接口下的子接口。
Stream<String> stream = list.stream(); // 获取一个顺序流
Stream<String> parallelStream = list.parallelStream(); //获取一个并行流
2
3
数组创建流
// Java8 中的 Arrays 的静态方法 stream() 可以获取数组流:
Integer[] numArrays = new Integer[5];
Stream<Integer> integerStream = Arrays.stream(numArrays);
2
3
由值创建流
// 可以使用静态方法 Stream.of(), 通过显示值 创建一个流。它可以接收任意数量的参数。
Stream<Integer> ofStream = Stream.of(1,2,3,4,5,6);
2
由函数创建流:创建无限流
// 可以使用静态方法 Stream.iterate() 和 Stream.generate(), 创建无限流。
// 迭代
Stream<Integer> stream = Stream.iterate(0, (x) -> x + 2).limit(10);
stream.forEach(System.out::println);
// 生成
Stream<Double> stream2 = Stream.generate(Math::random).limit(5);
stream2.forEach(System.out::println);
2
3
4
5
6
7
8
9
# 中间操作
多个中间操作可以连接起来形成一个流水管道。
除非流水管道上触发终止操作,否则中间操作不会执行任何的处理!
而在终止操作时一次性全部处理中间操作,所以它被称为 惰性求值。
可以看看下面这个例子:
//所有的中间操作不会做任何的处理
Stream<Integer> stream = Stream.of(1, 2, 3, 4, 5).filter(item -> {
System.out.println("中间操作");
return item < 2;
});
//只有当做终止操作时,所有的中间操作会一次性的全部执行,这就叫“惰性求值”
stream.forEach(System.out::println);
2
3
4
5
6
7
而 Stream 的中间操作可以分为三大类:
- 筛选,切片(我觉得它应该叫 过滤)
- 映射
- 排序
# 筛选、切片、过滤
在 Stream 当中,我觉得最为常用的应该就是过滤了,因为它确实很好用。
| 方 法 | 说 明 |
|---|---|
| filter(Predicate predicate) | 从流中排除某些元素。 |
| distinct() | 去重,通过流所生成元素的 hashCode() 和 equals()方法去除重复元素。 |
| limit(long maxSize) | 截流,使其元素不超过给定数量。 |
| skip(long n) | 跳过元素,返回一个扔掉前 n 个元素的流。若流中元素不足 n 个,则返回一个空流。 |
filter示例
@Test
public void test() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
// 过滤值大于3的值
list.stream().filter(item -> {
return item > 3;
}).forEach(System.out::println);
// 打印 4 5
}
2
3
4
5
6
7
8
9
distinct示例
@Test
public void test2() {
List<String> list = Arrays.asList("aaa", "aaa", "bbb", "ccc", "bbb");
list.stream().distinct().forEach(System.out::println);
// 打印 aaa bbb ccc
}
2
3
4
5
6
limit示例
@Test
public void test3() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream().limit(2).forEach(System.out::println);
// 打印 1 2
}
2
3
4
5
6
skip示例
@Test
public void test4() {
List<Integer> list = Arrays.asList(1, 2, 3, 4, 5);
list.stream().skip(2).forEach(System.out::println);
// 打印 3 4 5
}
2
3
4
5
6
# 映射
在 stream 流的中间操作当中,映射同样是使用率较高的,它可以为我们单独抽离流中的数据,方便后续处理。
| 方 法 | 说 明 |
|---|---|
| map(Function f) | 接受一个函数作为参数,该函数会被应用到每个元素上,并将其映射成一个新的元素。 |
| flatMap | 接收一个函数作为参数,将流中的每个值都换成另一个流,然后把所有流转为成一个流。 |
| mapToDouble(ToDubleFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的DoubleStream。 |
| mapToInt(ToIntFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的IntStream。 |
| mapToLong(ToLongFunction f) | 接收一个函数作为参数,该函数会被应用到每个元素上,产生一个新的LongStream。 |
| MapTo... | ... |
在上述API表中最为重要的,就是map和flatMap方法,因为使用的最多的也是这两个方法。
map示例
@Test
public void test5() {
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
list.stream().map(student -> student.getName()).forEach(System.out::print);
// 浅梦唐昊唐三小刚清河
}
2
3
4
5
6
7
8
9
10
11
12
flatMap示例
flatMap 意为扁平化map,如下方示例所示,我们需要将list中的字母,分别提取出来输出。
// 先写一过滤字符串获得一个字符串流的方法
public static Stream<Character> filterCharacter(String str){
List<Character> list = new ArrayList();
for (Character c : str.toCharArray()) {
list.add(c);
}
return list.stream();
}
@Test
public void test(){
List<String> list = Arrays.asList("aaa", "bbb", "ccc", "ddd");
Stream<Stream<Character>> stream = list.stream().map(str -> filterCharacter(str));
// 如果使用map,可以看出在流中仍然是一个流,流中才是字符串。
// 那么我们提取出来遍历就需要这样写
stream.forEach(sm -> sm.forEach(System.out::print));
System.out.println("\n=============");
// 如果我们使用flatMap,就可以解决这一个问题了。它会将map提取出来的元素一个一个的放进一个流中。
// 可以理解为平时我们使用list时,可以 add(对象)。
// 当我们有两个lsit需要合并在一起时,我们使用 addAll(集合) 方法,最后得到结果list。
// flatMap 其实也是一样的,它直接map提取出的流最终合并到一个流当中。
Stream<Character> stream2 = list.stream().flatMap(str -> filterCharacter(str));
stream2.forEach(System.out::print);
// 输出如下:
// aaabbbcccddd
// =============
// aaabbbcccddd
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
# 排序
很多时候,我们都会对一个集合当中的数据进行一些排序,毕竟做需求基本上离不开排序,而 Stream 流的中间操作也为我们提供了排序的API。
| 方 法 | 说 明 |
|---|---|
| sorted() | 产生一个新的流,其中按自然顺序排序 |
| sorted(Comparator comp) | 产生一个新的流,其中按比较器顺序排序 |
自然排序在这里就不进行过多的示例说明了,因为它是官方实现的字典排序,其中的元素必须实现 Comparable 接口。
而我们做需求时,往往是各种各样的排序,需要自己定义,这就需要使用到了 sorted(Comparator comp) 。
示例:根据学生的成绩从低到高排序,并提取他们的成绩。
@Test
public void test(){
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
list.stream()
.sorted((x, y) -> x.getScore().compareTo(y.getScore()))
.map(Student::getScore)
.forEach(System.out::println);
}
2
3
4
5
6
7
8
9
10
11
12
13
14
从上述例子中,我们可以看到使用了sorted的方法,使用 lambda表达式来申明一个排序方法,并使用map提取对象中的score信息,最后使用 forEach遍历输出。
# 终止操作
上述已经表明了,一个流如果没有终止操作,那么它并不会执行,称之为**"惰性求值"**。
所以我们需要从流水管道中生成结果,而这就是所谓的终止操作,也称之为终端操作。
它分为三种:
- 查找与匹配
- 归约
- 收集
# 查找与匹配
| 方 法 | 说 明 |
|---|---|
| allMatch(Predicate p) | 检查是否匹配所有元素 |
| anyMatch(Predicate p) | 检查是否至少匹配一个元素 |
| noneMatch(Predicate p) | 检查是否没有匹配所有元素 |
| findFirst() | 返回第一个元素 |
| findAny() | 返回当前流中的任意元素 |
| count() | 返回流中元素总数 |
| max(Comparator c) | 返回流中最大值 |
| min(Comparator c) | 返回流中最小值 |
| forEach(Consumer c) | 内部迭代(使用Collection接口需要用户去做迭代,成为外部迭代。相反,Stream API 使用内部迭代 --- 也就是说它已经帮你完成了) |
请容许我使用一个大型的方法来表示上面这堆API的示例
@Test
public void test() {
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
// allMatch示例:
// 需求:是否全部学生成绩及格?,及格分数为大于等于60
boolean is = list.stream().allMatch(item -> item.getScore() >= 60);
System.out.println("全部成绩及格吗?" + is);
// anyMatch示例:
// 需求:是否有小于15岁的学生?
boolean is2 = list.stream().anyMatch(item -> item.getAge() <= 15);
System.out.println("有学生小于15岁吗?" + is2);
// noneMatch示例:
// 需求:是否全部学生的名字都没有三个字?
boolean is3 = list.stream().noneMatch(item -> item.getName().length() == 3);
System.out.println("全部学生的名字都是两个字吗?" + is3);
// findFirst示例:
// 获取一个最高成绩的学生名称
Optional<String> opt = list.stream()
.sorted((x, y) -> y.getScore().compareTo(x.getScore()))
.map(Student::getName).findFirst();
System.out.println("最高成绩的学生叫:" + opt.get());
// findAny示例:效率高
// 这里是返回任意一个学生,findAny在并行流时会有效果可以看出。
// 如果是stream,那么它一般会返回第一个。
Optional<Student> any = list.parallelStream().findAny();
System.out.println(any.get().getName());
// count示例:
long count = list.stream().count();
System.out.println("总共有" + count + "个学生。");
// max示例:
Optional<Integer> max = list.stream()
.map(item -> item.getAge())
.max((age1, age2) -> age1.compareTo(age2));
System.out.println("学生的最大年龄是:" + max.get());
// min示例:
Optional<Integer> min = list.stream()
.map(item -> item.getAge())
.min((age1, age2) -> age1.compareTo(age2));
System.out.println("学生的最小年龄是:" + min.get());
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
你可以从上述的示例中轻松理解它们各自的用法。
# 归约
| 方 法 | 说 明 |
|---|---|
| reduce(T iden, BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 T |
| reduce(BinaryOperator b) | 可以将流中元素反复结合起来,得到一个值。返回 Optional<T> |
@Test
public void test(){
List<Integer> list = Arrays.asList(1,2,3,4,5,6,7,8,9,10);
Integer sum = list.stream().reduce(0, (x,y) -> x + y);
System.out.println(sum); // 输出55
}
2
3
4
5
6
我们重点留意list.stream().reduce(0, (x,y) -> x + y);。
首先从 0 开始,第一次赋予 x 为 0,然后将list当中的第一个元素赋予y,执行 x + y。
第二次就将x + y的结果赋予给参数 x ,然后在从 list 当中获取第二个元素赋予 y ,再执行 x + y。
第三次以此类推,结果就是list当中所有相加的结果。
归约在
map和reduce的连接通常称为map-reduce模式,因为 Google 用它来进行网络搜索而出名。
@Test
public void test(){
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
Optional<Double> optSum = list.stream().map(Student::getScore).reduce(Double::sum);
System.out.println("全班总成绩:" + optSum.get());
}
2
3
4
5
6
7
8
9
10
11
12
# 收集
收集是我们日常使用率最高的一个流终止操作,一般情况下,我们需要对一个集合进行一次过滤,然后再进行排序,最后我们需要获取一个新的结合,这时通常使用collect。
| 方 法 | 说 明 |
|---|---|
| collect(Collector c) | 将流转换为其他形式,接收一个Collector接口的实现,给Stream中元素做汇总的方法 |
@Test
public void collectTest(){
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
List<Student> newList = list.stream() // 获取流
.filter(item -> item.getAge() < 20) // 过滤
.sorted((x, y) -> -x.getScore().compareTo(y.getScore())) // 排序
.collect(Collectors.toList());// 收集
System.out.println(newList);
// [Student{id=3, name='唐三', age=16, score=92.11},
// Student{id=1, name='浅梦', age=13, score=88.99}]
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
collect接收的参数为Collector,而 Java 8 为我们提供了 Collectors 的静态工厂类,该类中有大量的静态方法提供给我们使用,足以应付日常需求,比如上述的toList方法。
它还有toSet、toMap、toCollection、groupingBy、counting 等等...
下面使用一个大的示例包含目前常用的一些Collectors的静态方法。
@Test
public void collectTest() {
List<Student> list = Arrays.asList(
new Student(1, "浅梦", 13, 88.99),
new Student(2, "唐昊", 27, 97.99),
new Student(3, "唐三", 16, 92.11),
new Student(4, "小刚", 30, 50.00),
new Student(5, "清河", 30, 77.00)
);
// toSet 转为set
Set<Student> set = list.stream().collect(Collectors.toSet());
// toMap 转为map
Map<Integer, Student> map = list.stream()
.collect(Collectors.toMap(student -> student.getId(), student -> student));
// toCollection 转换为想要的类型,类型必须有继承Collection的关系。
LinkedHashSet<Student> linkedHashSet = list.stream()
.collect(Collectors.toCollection(LinkedHashSet::new));
// counting 收集总数
Long count = list.stream().collect(Collectors.counting());
// summing 收集总和
Integer ageSum = list.stream().collect(Collectors.summingInt(Student::getAge));
Double scoreSum = list.stream().collect(Collectors.summingDouble(Student::getScore));
// avging 收集平均值
Double avgAge = list.stream().collect(Collectors.averagingInt(Student::getAge));
// summarizing 收集流中的统计值,返回统计对象。
IntSummaryStatistics statistics = list.stream().collect(Collectors.summarizingInt(Student::getAge));
statistics.getMax();
statistics.getCount();
// ...
// joining 连接流中的字符串
String str = list.stream()
.map(Student::getName)
.collect(Collectors.joining());
String str2 = list.stream()
.map(Student::getName)
.collect(Collectors.joining(","));
String str3 = list.stream()
.map(Student::getName)
.collect(Collectors.joining(",", "===", "==="));
// maxBy minBy 根据比较器选择最大最小值
Optional<Student> optStu = list.stream()
.collect(Collectors.maxBy((x, y) -> x.getScore().compareTo(y.getScore())));
Optional<Student> optStu2 = list.stream()
.collect(Collectors.minBy((x, y) -> x.getScore().compareTo(y.getScore())));
// groupingBy 分组
// 根据学生年龄进行分组
Map<String, List<Student>> groupStudent =
list.stream().collect(Collectors.groupingBy(item -> {
if (item.getAge() <= 25) {
return "青年";
} else if (item.getAge() <= 30) {
return "中年";
} else {
return "老年";
}
}));
// partitioningBy 根据true 和 false 进行分区
// 根据学生成绩获取合格和不合格的分区map
Map<Boolean, List<Student>> partMap =
list.stream().collect(Collectors.partitioningBy(item -> {
if (item.getScore() >= 60) {
return true;
}
return false;
}));
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
37
38
39
40
41
42
43
44
45
46
47
48
49
50
51
52
53
54
55
56
57
58
59
60
61
62
63
64
65
66
67
68
69
70
71
72
73
74
75
76
77
78
79
# 并行流和串行流
并行流就是把一个内容分成多个数据块,并用不同的线程分别处理每个数据块的流。
一般使用的stream属于串行流,串行流也称顺序流,按顺序执行指令。
而我们可以通过stream API的parallel()和sequential()在并行流和串行流之间进行切换。
# 什么是并行流?
并行流其实是 Fork/Join 框架演变过来的,而 Fork/Join 框架早在 Java 7 的时候已经引入了。
但是因为使用起来相对比较麻烦,所以并没有大范围的投入到日常使用中。
所以 Java 8 对其进行了优化,使它用起来足够的优雅。
# Fork/Join 框架
在这里不得不说一下 Fork/join框架,它到底做了些什么呢?
它其实就是将一个大的任务,拆分成若干个小任务执行,最后将这些小任务运算的结果进行 join 合并汇总。
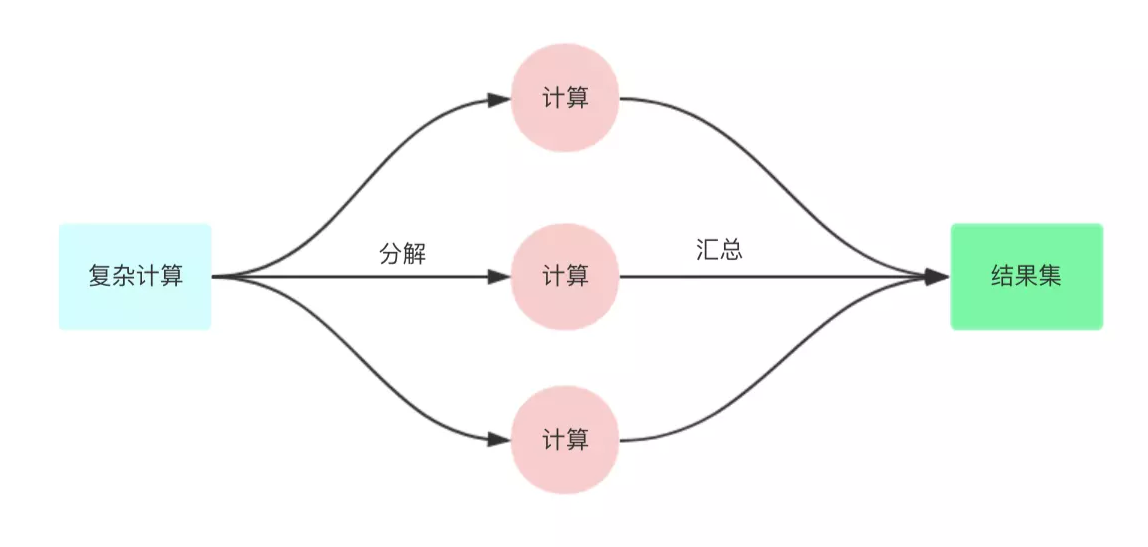
在数据量大的时候,它的性能更优于传统的线程池方式。
Fork/join框架和线程池的区别在于它采用了 “工作窃取” 模式。
当执行新的任务时它可以将其拆分成更小的任务执行,并将小任务加到线程队列中,然后在从随机一个线程队列中偷一个任务并把它放在自己的队列中。
相对于一般的线程池实现,它可以更加高效的利用 CPU 的资源,当使用传统的线程池方式时,如果线程阻塞了,那么该线程会一直处于等待状态。如果是 Fork/join框架,当阻塞时,它会去窃取其他的任务执行,这种方式减少了线程的等待时间,大大提高了性能。
那么为什么在性能更优于线程池的 Fork/join在实际开发中运用比传统的线程池使用率少呢?
因为它写起来实在是有点繁琐,可以看一个具体的实现例子:
数字累加例子:
/**
* ForkJoin 实现
*/
public class ForkJoinCalculate extends RecursiveTask<Long>{
private static final long serialVersionUID = 12371298582392L;
private long start;
private long end;
private static final long THRESHOLD = 10000L; //临界值
public ForkJoinCalculate(long start, long end) {
this.start = start;
this.end = end;
}
@Override
protected Long compute() {
long length = end - start;
if(length <= THRESHOLD){
long sum = 0;
for (long i = start; i <= end; i++) {
sum += i;
}
return sum;
}else{
long middle = (start + end) / 2;
ForkJoinCalculate left = new ForkJoinCalculate(start, middle);
left.fork(); //拆分,并将该子任务压入线程队列
ForkJoinCalculate right = new ForkJoinCalculate(middle+1, end);
right.fork();
return left.join() + right.join();
}
}
}
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
21
22
23
24
25
26
27
28
29
30
31
32
33
34
35
36
@Test
public void test(){
long start = System.currentTimeMillis();
// 创建一个 ForkJoin 的线程池
ForkJoinPool pool = new ForkJoinPool();
// 创建 ForkJoinTask 的实例
ForkJoinTask<Long> task = new ForkJoinCalculate(0L, 10000000000L);
// 提交执行
long sum = pool.invoke(task);
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗费的时间为: " + (end - start));
}
2
3
4
5
6
7
8
9
10
11
12
13
可以看到的一大串代码,只为了实现这么一个功能:
public void test2(){
long sum = 0;
for(long i = 0; i < 10000000000L; i++){
sum += i;
}
System.out.println(sum);
}
2
3
4
5
6
7
看到这里,你应该对Fork/join框架有了个大致的了解了。
# Stream 并行流
在上述的示例中你可以了解到 Fork/join框架的具体作用。
而在 Java 8 当中,它对 Fork/join 框架进行了优化,并使 Stream 流支持 Fork/join。
我们只需要在使用 Stream 流中申明性地通过 parallel() 和sequential()在并行流和串行流之间进行切换即可。
示例:
@Test
public void test3(){
long start = System.currentTimeMillis();
Long sum = LongStream.rangeClosed(0L, 10000000000L)
.parallel()
.sum();
System.out.println(sum);
long end = System.currentTimeMillis();
System.out.println("耗费的时间为: " + (end - start));
}
2
3
4
5
6
7
8
9
10